Redis中的SDS
本文共 4256 字,大约阅读时间需要 14 分钟。
SDS
redis操作数据为什么会快?在回答这个问题时,我们一般会说redis对数据的操作是基于缓存的,速度自然而然的快。二来redis在数据操作时通过单线程模型避免了线程切换产生的开销。除此之外,redis采用的合理的数据结构也是redis操作数据快的原因之一。
简单动态字符串
Redis支持字符串类型的操作,其底层实现却不是采用C语言表示字符串的方式,而是采用SDS(simple dynamic string,简单动态字符串) 抽象类型进行表示。
结构
在redis5.0的sds.h源码文件中,定义了多个长度类型的SDS。
len表示实际使用的长度alloc表示已经分配的长度,不包括头部和空的终止符号(\0)flags表示那种类型的SDS,根据源码,redis提供了5种数据类型的SDS,采用二进制表示,用低3位即可表示。buf存放字符串的字节数组。
/* Note: sdshdr5 is never used, we just access the flags byte directly. * However is here to document the layout of type 5 SDS strings. */struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[];};struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];}; 原理
以set msg "hello world!"为例子:redis会创建一个新的键值对,而关于键msg和值 "hello world!"的表示,则是采用SDS的方式进行实现。
- 首先通过计算初始字符串长度决定创建那种数据类型的SDS。
- 通过
sdsHdrSize函数得到待创键的SDS的大小hdrlen - 为sh指针分配一个
hdrlen+initlen+1大小的堆内存(+1是为了放置’0’,这个’0’不计入alloc或len) - 初始化变量len、alloc和flags
- 用memcpy给sds赋值,并在尾部加上’0’
/* Create a new sds string with the content specified by the 'init' pointer - and 'initlen'. - If NULL is used for 'init' the string is initialized with zero bytes. - If SDS_NOINIT is used, the buffer is left uninitialized; - 5. The string is always null-termined (all the sds strings are, always) so - even if you create an sds string with: - 8. mystring = sdsnewlen("abc",3); - 10. You can print the string with printf() as there is an implicit \0 at the - end of the string. However the string is binary safe and can contain - \0 characters in the middle, as the length is stored in the sds header. */sds sdsnewlen(const void *init, size_t initlen) { void *sh; sds s; char type = sdsReqType(initlen); /* Empty strings are usually created in order to append. Use type 8 * since type 5 is not good at this. */ if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; int hdrlen = sdsHdrSize(type); unsigned char *fp; /* flags pointer. */ sh = s_malloc(hdrlen+initlen+1); if (init==SDS_NOINIT) init = NULL; else if (!init) memset(sh, 0, hdrlen+initlen+1); if (sh == NULL) return NULL; s = (char*)sh+hdrlen; fp = ((unsigned char*)s)-1; switch(type) { case SDS_TYPE_5: { *fp = type | (initlen << SDS_TYPE_BITS); break; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } } if (initlen && init) memcpy(s, init, initlen); s[initlen] = '\0'; return s;} 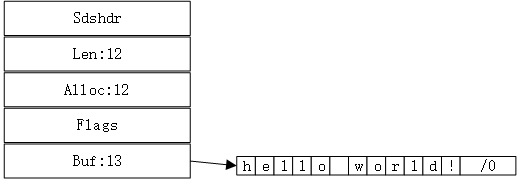
优势
为什么redis采用SDS的方式来保存字符串呢?假设采用C语言表示字符串的原始方式,我们可以发现:
- 当我们对保存的字符串进行修改的时候,如果修改完的字符串比原来的大,原来的空间如果存放不下,此时则会发生内存溢出。
- 当修改完的字符半小了,累计出来的多余空间若是没有及时释放,则会有内存泄漏的风险。
- 为了应对上述两种情况,需要不断进行内存重新分配,但过多的内存重新分配又是耗性能的事情。
- 另外,当对字符创长度统计时,需要进行读取,直到"/0"为止,时间复杂度为O(n)。
采用SDS的方式进行保存后,虽然表示方式复杂了一点,但考虑后边数据的操作性能上,则是很好的提升。
- 通过len记录字符串实际长度,使得访问字符串长度时,时间消耗为O(1)
- 通过alloc记录已经分配的空间信息,降低内存分配次数
转载地址:http://dlxm.baihongyu.com/
你可能感兴趣的文章
MySQL更新锁(for update)摘要
查看>>
MySQL服务器安装(Linux)
查看>>
mysql服务器查询慢原因分析方法
查看>>
mysql服务无法启动的问题
查看>>
mysql权限
查看>>
mysql条件查询
查看>>
MySQL架构与SQL的执行流程_1
查看>>
mysql查询储存过程,函数,触发过程
查看>>
mysql查询总成绩的前3名学生信息
查看>>
mysql的cast函数
查看>>
mysql的InnoDB引擎索引为什么使用B+Tree
查看>>
mysql的logrotate脚本
查看>>
MySQL的on duplicate key update 的使用
查看>>
mysql的root用户无法建库的问题
查看>>
mysql的sql语句基本练习
查看>>
Mysql的timestamp(时间戳)详解以及2038问题的解决方案
查看>>
MySQL的常见命令
查看>>
mysql的数据类型有哪些?
查看>>
MySQL的错误:No query specified
查看>>
mysql索引
查看>>